What do European say when they talk about GAFAM?
THE ISSUE
What media say when they talk about GAFAM? How do GAFAM represent their role in the society? Do these representations match? Despite the ubiquity of the discourse on the dominant role that large platforms play in the society and in the economy, as well as on the alleged influence that these latter yield on the public discourse, there is dearth of empirical analysis on this. On the one hand, many maintain that GAFAM have built a hegemonic discourse on their irreplaceability and on their role as the engine of a beneficial technological revolution and economic growth. Others contend that platforms are becoming objects of political contention and debate, moving out of their former position of a naturalized state of centrality.
THE STUDY
By the means of a thoughtful analysis of both European media discourse and GAFAM corporate speech, we provide a portrait of what media say when they talk about GAFAM as well as how these latter represent themselves.
To tackle with these questions, we studied a corpus of texts that includes both GAFAM’s corporate speech in the last fifteen years and the discourse regarding GAFAM as it emerges in European media outletsin the same time period. We investigate whether common themes emerge and, eventually, what the difference are in framing the same themes.
The media data set covers 17 European countries (Austria, Belgium, Bulgaria, Czech Republic, Denmark, Estonia, Finland, France, Germany, Ireland, Italy, Netherlands, Poland, Portugal, Spain, Switzerland and the United Kingdom) and was primarily obtained from the Dow Jones Factiva database. It contains 92,569 articles. The GAFAM data set was collected from the websites of the companies themselves and contains 20,554 texts. The combined dataset for this analysis is thus made up of 113,123 texts.
ANALYSIS OF TOPICS
The corpus of texts was analysed using an algorithmic method called topic modelling, which is able to detect general themes and discourses that are present in the data1. We analyzed 185 topics over this time span. To each of these topics we associated a sentiment2, an optimistic or an adversarial attitude, and for each of these topics it is possible to trace a timeline that represents the average prevalence of that particular topic in the analysed texts.
THE RESULTS: AN OVERVIEW
In general, our research highlights the following facts:
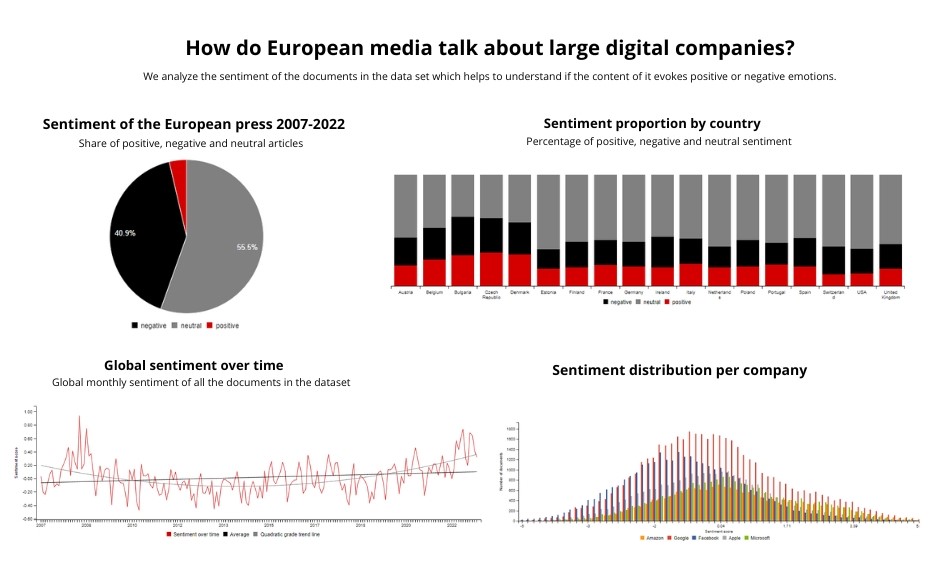
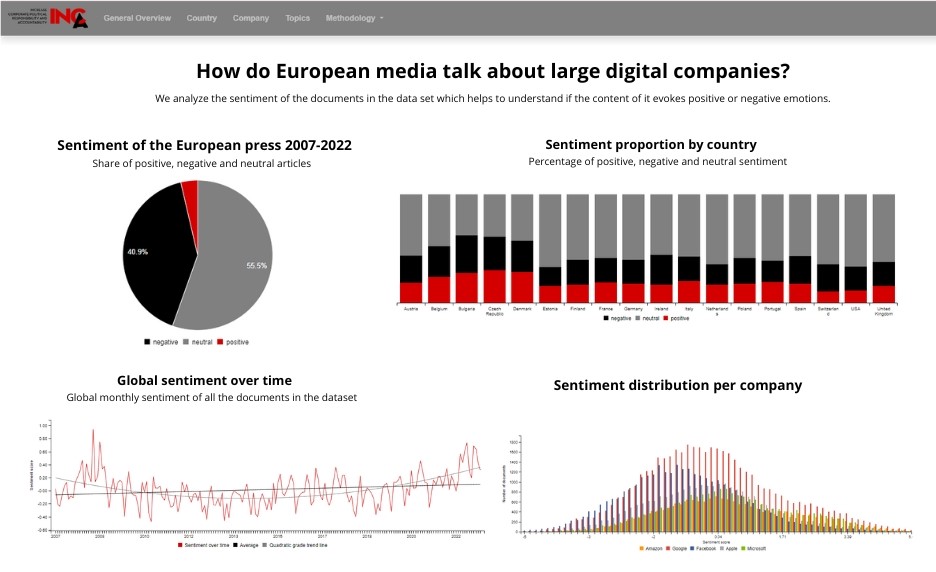
- The articles that we analysed do not show a positive attitude towards GAFAM. We found that nearly 40% of the newspaper articles have a clear negative sentiment towards GAFAM companies and less than 5% of the articles have a clear positive sentiment.
- There are a number of topics that particularly express concern in relation to the misbehaviour of GAFAM. The issues that are most worrying regard the misbehaviour on internet, the violation of privacy right, the transparency of political campaigning on the internet. In addition, media articles stigmatize alleged tax evasion associated with gigantic profits and monopolistic attitude. Overall, in the analysed articles a strong request is voiced for the regulation of GAFAM activity.
- Sentiment towards GAFAM is different in different European countries. Bulgaria, for example, is the country in which negative sentiment is largely diffused while Estonia has the smallest share of articles that convey a negative sentiment.
- In general, the sentiment towards GAFAM has changed in the analysed period. For example, while in Italy the sentiment remained stable, or slightly improved, in Estonia, which in general shows a good attitude towards GAFAM, the sentiment has slightly worsened. The highlight section on the website allows analysing the sentiment trend over time of all the documents in the dataset. Using a simple graph, it is possible to have a complete view of the moments during the analysed period (2007-2022) in which the general sentiment was particularly negative and those in which it was positive.
- Focusing on the companies, our data shows that Facebook is the company associated with the most negative sentiment, while Apple and Microsoft are the most positive. Data on sentiment can be associated to specific companies; therefore it is possible to enquire the website in order to extract how the sentiment towards specific companies unfolded overt time.
One key aim of INCA project is to contribute to improve the transparency of information regarding the activity of large digital platforms. We believe that it is important for individuals to directly access the results of our research. Therefore, the INCA website (www.inca-project.eu) makes available a user interface that allows to search and extract the information collected.
SEARCH FOR YOUR INFORMATION
The section “highlights” of the website (www.inca-project.eu/highlights) gives the opportunity to conduct personal searches for the data. For example, it is possible to analyse the sentiment trend over time of all the documents in the dataset. Using a simple graph, it is possible to have a complete view of the moments during the analysed period (2007-2022) in which the general sentiment was particularly negative and those in which it was positive. The analysis of this trend can be as well performed for each of the considered countries. It is also possible to observe the sentiment trend towards each of the analysed companies.
In general, by navigating the highlight section of the INCA website, it is possible to conduct the following queries:
- Analyse the sentiment trend towards the GAFAM companies focusing only on one single country.
- Analyse documents from all the countries searching by single company.
- See the share of documents bearing a positive or negative attitude about a company for every country.
In addition, in the highlight section, there is a page specifically dedicated to information about topics where it is possible to compare the prevalence of every topic in the analysed documents.
Furthermore, for every topic, it is possible to visualize a series of information: the topic’s wordcloud (the cluster that includes the most important words of the topic), the relative sentiment trend which helps to understand which were the moments in time in which the topic had a positive sentiment and the moments in which it was negative, and the prominence that visualize when the topic was more present in the public discourse of every country during the analysed period.
Edoardo Mollona, INCA project coordinator, University of Bologna
Martin Molder, University of Tartu
- Topics are the result of the execution of a topic modelling algorithm that extracts the topics present in a collection of documents by detecting clusters of words that co-occur frequently and help to differentiate between texts. ↩︎
- Sentiment is the output of the execution of sentiment analysis algorithms over all the documents of the collection. The aggregation of the output is a value that indicates if the document has a positive or negative sentiment. ↩︎